You've Got to Feel It To Believe It: Multi-Modal Bayesian Inference for Semantic and Property Prediction
We incorporate both visual and tactile information to improve semantic maps for robots.
 For more information, see the project webpage
For more information, see the project webpage
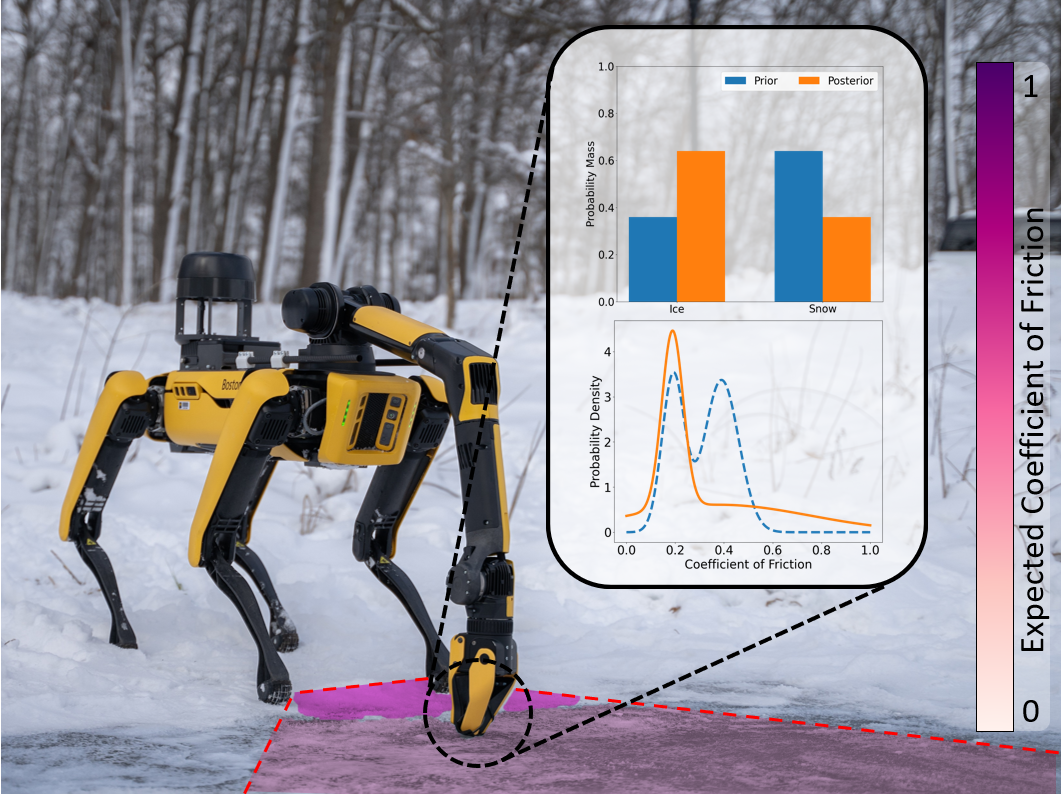
Robots must understand their surroundings to perform complex tasks, often requiring estimates of physical properties like friction or weight. This paper introduces a novel multi-modal approach that uses conjugate pairs for joint probabilistic representation of semantic predictions and physical property estimates, enabling closed-form Bayesian updates with visual and tactile data. The proposed method quantitatively outperforms state-of-the-art semantic classification methods relying solely on vision and demonstrates its utility in various applications, including affordance-based properties and terrain traversal with a legged robot. Videos and the open-source interface are available at the project webpage*.
{kind=link}
Discover more...
These Magic Moments: Differentiable Uncertainty Quantification of Radiance Field Models
ConvBKI: Real-Time Probabilistic Semantic Mapping Network with Quantifiable Uncertainty
